
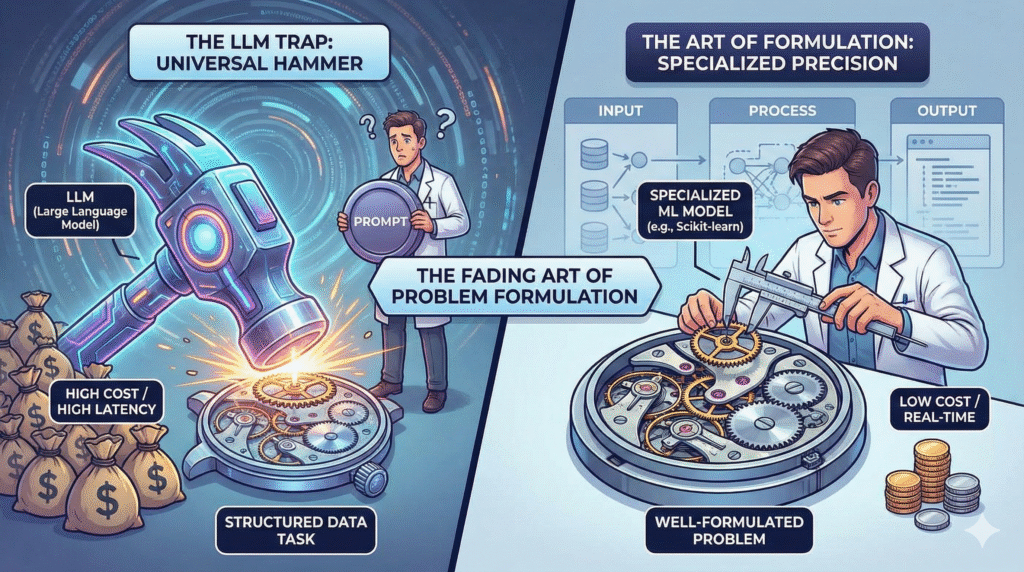
In the rush to embrace Large Language Models, a critical skill in data science is being overlooked: the art of problem formulation.
The data science landscape is evolving at a dizzying pace, with Large Language Models (LLMs) like GPT-4 capturing headlines and imaginations. Their versatility is undeniable, leading many to view them as a universal solution for almost any problem. However, this enthusiasm often overshadows a fundamental principle of effective data science: rigorous problem formulation. We’re witnessing a concerning trend where the nuanced process of defining a problem for machine learning is being replaced by a simplistic ‘prompting’ mindset, potentially leading to inefficient, costly, and suboptimal solutions.
The Core Issue: Beyond the Single Hammer
A complex business challenge, such as detecting fraudulent transactions, is rarely a one-size-fits-all machine learning task. It demands careful consideration of data availability, performance requirements, and operational constraints. Instead of immediately reaching for the most powerful tool, a seasoned data scientist understands that the same problem can be formulated in multiple, equally valid ways, each with distinct implications:
* Supervised Classification (The Standard Approach): If you have a rich dataset of historical transactions clearly labeled as ‘fraudulent’ or ‘legitimate,’ this is often the most straightforward approach. Models like Logistic Regression, Random Forests, or Gradient Boosting (implementable with libraries like Scikit-learn in Python) can be trained to classify new transactions based on learned patterns. This method excels when labels are abundant and reliable.
* Unsupervised Clustering / Outlier Detection: What if labeled fraud data is scarce, or fraud patterns constantly evolve? Here, the problem can be reframed as an outlier detection task. Algorithms like Isolation Forests or One-Class SVMs can identify transactions that deviate significantly from the norm, flagging them for further investigation. This approach is powerful for discovering novel fraud schemes without explicit prior examples.
* Hybrid Approaches (Dimensionality Reduction + Rule-Based Logic): Sometimes, a blend of techniques is best. Dimensionality reduction (e.g., PCA) can simplify complex transaction data, making it easier to identify key features. This reduced representation can then be fed into simpler models or combined with expert-defined rule-based logic to catch specific, known fraud patterns. This offers a balance between data-driven insights and business domain knowledge.
Each of these formulations requires different data preparation, model selection, and evaluation metrics. The choice isn’t arbitrary; it’s a strategic decision based on the specific context and available resources.
The LLM Trap: Universal Learners vs. Specialized Efficiency
The allure of LLMs is their perceived universality. Why bother with specialized models when a single, powerful LLM can seemingly answer any question? This mindset, however, often overlooks critical model efficiency and cost-benefit analysis.
Consider the stark contrast in operational costs and latency:
* LLM Cost: An interaction with a sophisticated LLM like GPT-4 via the OpenAI API might cost around $0.05 per 1,000 tokens. While seemingly small, this adds up rapidly for high-volume applications and comes with inherent high latency due to API calls and complex inference.
* Custom Classifier: A well-optimized, specialized machine learning model (e.g., a simple Logistic Regression or a small Gradient Boosting model) can be incredibly efficient. It might have a memory footprint of just 8MB and run inference on a standard CPU for fractions of a cent, potentially costing $0.0001 per inference or less, with near-real-time latency.
We are seeing a generation of ‘AI Engineers’ who, armed with powerful APIs, default to `response = openai.chat.completions.create(model=’gpt-4′, …)` for every problem. This approach, while easy to implement initially, often ignores the profound trade-offs in terms of cost, latency, scalability, and explainability. It’s a classic case of convenience trumping efficiency and strategic thinking.
Real-World Application: Fraudulent Transaction Detection
Let’s concretize this with our real-world use case: detecting fraudulent financial transactions. A bank processes millions of transactions daily, and identifying fraud quickly and accurately is paramount.
Traditional ML Approach (e.g., Supervised Classification with Scikit-learn): A data scientist would use Pandas to preprocess transaction data (features like transaction amount, location, time, merchant, etc.), train a classifier on historical labeled data, and deploy it. This model would run locally or on dedicated infrastructure, offering low latency and predictable costs, flagging suspicious transactions in milliseconds. The model’s decisions are often explainable, allowing analysts to understand why* a transaction was flagged.
* LLM-Based Approach: An ‘AI Engineer’ might feed the raw transaction details (e.g., ‘User X spent $500 at an unknown merchant in a foreign country at 3 AM’) into an LLM and ask, ‘Is this transaction fraudulent?’ While the LLM might provide a plausible answer, the implications are significant:
* Cost: Each query incurs a token cost, quickly becoming prohibitive at scale.
* Latency: API calls introduce delays, which are unacceptable for real-time fraud prevention.
* Explainability: The LLM’s reasoning is often opaque, making it difficult to audit or justify decisions to regulators or customers.
* Accuracy & Hallucination: LLMs are not designed for precise numerical classification and can ‘hallucinate’ or provide incorrect justifications, leading to false positives or, worse, missed fraud.
The difference isn’t just academic; it’s about building robust, scalable, and economically viable solutions.
Reclaiming the Art: Prioritizing Problem Formulation and Trade-offs
The solution isn’t to abandon LLMs, but to understand their appropriate place. They are phenomenal for tasks like content generation, summarization, and complex natural language understanding where their creativity and breadth of knowledge shine. However, for structured data classification, high-throughput, low-latency decision-making, and tasks requiring strict explainability, specialized machine learning models remain superior.
Data scientists must re-emphasize the importance of:
* Deep Business Understanding: Truly grasping the problem, its constraints, and its impact.
* Data-Driven Formulation: Choosing the right ML paradigm based on data availability and characteristics.
* Model Efficiency and Cost-Benefit Analysis: Evaluating solutions not just on accuracy, but on their total cost of ownership, latency, and scalability.
* Critical Thinking: Resisting the urge to apply a single ‘universal’ tool to every problem.
As the saying goes: ‘If all you have is a hammer (LLM), everything looks like a nail.’ It’s time to bring back the discussion on problem formulation and ensure that our pursuit of AI innovation is grounded in sound engineering principles and strategic thinking.
Critical Questions for the Modern Data Scientist
To foster this critical thinking, consider these questions:
* How can data scientists effectively evaluate the true total cost of ownership (TCO) and performance implications when choosing between specialized ML models and general-purpose LLMs for a specific business problem?
* What are the long-term risks and ethical considerations of over-relying on black-box LLM solutions for critical tasks like fraud detection, especially concerning explainability and bias?
* Beyond technical metrics, how can organizations foster a culture that prioritizes rigorous problem formulation and critical thinking over simply defaulting to the latest ‘universal’ AI tool?
This exploration highlights how combining sound theory with practical implementation can unlock meaningful real-world applications.The Neglected Art: Why Problem Formulation, Not Just LLMs, Drives Effective Data Science
The rapid adoption of Large Language Models (LLMs) like GPT-4 has created a false sense of a “universal solution” in data science, overshadowing a far more critical discipline: rigorous problem formulation. This shift toward a simplistic ‘prompting’ mindset, instead of nuanced strategic thinking, risks generating inefficient, costly, and suboptimal outcomes .The Challenge of the One-Size-Fits-All Tool
Complex business problems, such as detecting fraudulent transactions, are rarely solved by a single machine learning approach. A seasoned data scientist recognizes that the problem can be framed in multiple, valid ways, each with unique operational and data implications:
| Formulation Type | Data Requirement & Best Use Case | Example Models & Libraries |
| Supervised Classification | Abundant, reliably labeled historical data. Ideal for known patterns. | Logistic Regression, Random Forests, Gradient Boosting (Scikit-learn in Python) |
| Unsupervised Clustering / Outlier Detection | Labeled data is scarce, or patterns constantly evolve. Ideal for discovering novel deviations. | Isolation Forests, One-Class SVMs |
| Hybrid Approaches | A blend of structured and unstructured data, requiring simplified representation and/or expert rules. | Dimensionality Reduction (PCA) combined with Rule-Based Logic |
The choice among these paradigms is a strategic decision dictated by available resources, data characteristics, and required performance metrics. The LLM Trap: Cost and Latency vs. Specialized Efficiency
The allure of LLMs is their perceived universality, yet this often ignores essential model efficiency and cost-benefit analysis.
| Metric | Specialized Custom Classifier | Sophisticated LLM (e.g., GPT-4 via API) |
| Operational Cost | Extremely low, often $0.0001 per inference or less. | High, approx. $0.05 per 1,000 tokens (rapidly accumulates at scale). |
| Latency | Near real-time, low latency (runs locally on CPU). | Inherent high latency due to API calls and complex inference. |
| Size/Footprint | Small (e.g., 8MB memory footprint). | Massive, relying on large cloud infrastructure. |
| Explainability | High; decisions are often explainable. | Low; reasoning is often opaque (“black box”). |
The current trend sees “AI Engineers” defaulting to LLM API calls for every task. While convenient initially, this approach ignores crucial trade-offs in cost, scalability, latency, and explainability, making it strategically unsound for high-throughput, structured data tasks. Real-World Case: Fraud Detection at Scale
In a critical, real-time application like banking fraud detection (processing millions of daily transactions):
- Traditional ML: A Supervised Classifier, preprocessed using tools like Pandas and trained with Scikit-learn, provides low-latency, predictable-cost, and explainable decisions, flagging transactions in milliseconds.
- LLM-Based Approach: Asking an LLM, “Is this transaction fraudulent?” incurs prohibitive token costs, unacceptable API call latency, and opaque reasoning, all while risking hallucination for a task requiring precise numerical classification.
The difference is the foundation of building an economically viable and robust solution. Reclaiming Strategic Thinking
The goal is not to eliminate LLMs, which excel at content generation and summarization, but to situate them appropriately. For structured data classification and high-throughput decision-making, specialized models remain superior.
Data scientists must re-focus on:
- Deep Business Understanding: Grasping the problem’s constraints and impact.
- Data-Driven Formulation: Selecting the correct ML paradigm based on data characteristics.
- Cost-Benefit and Efficiency Analysis: Evaluating total cost of ownership (TCO), latency, and scalability, not just accuracy.
- Critical Thinking: Resisting the default application of a single “universal” tool.
The discussion must return to problem formulation to ensure AI innovation is anchored in sound engineering principles. As the maxim states, “If all you have is a hammer (LLM), everything looks like a nail.” It is time to diversify our toolkit and elevate our strategic thinking.